Hash-kort i Python
Hash-kort er indekserede datastrukturer. Et hash-kort gør brug af en hash funktion at beregne et indeks med en nøgle i en række af spande eller slots. Dens værdi tilknyttes bucket med det tilsvarende indeks. Nøglen er unik og uforanderlig. Tænk på et hash-kort som et skab med skuffer med etiketter til de ting, der er gemt i dem. For eksempel lagring af brugeroplysninger - betragte e-mail som nøglen, og vi kan kortlægge værdier, der svarer til den bruger, såsom fornavn, efternavn osv. til en bucket.
Hash-funktion er kernen i implementering af et hash-kort. Den tager nøglen ind og oversætter den til indekset for en spand i spandlisten. Ideel hashing bør producere et forskelligt indeks for hver nøgle. Dog kan kollisioner forekomme. Når hashing giver et eksisterende indeks, kan vi blot bruge en bucket til flere værdier ved at tilføje en liste eller ved at genhashing.
I Python er ordbøger eksempler på hash-kort. Vi vil se implementeringen af hash-kort fra bunden for at lære, hvordan man bygger og tilpasser sådanne datastrukturer til optimering af søgning.
Hashkortets design vil omfatte følgende funktioner:
- set_val(nøgle, værdi): Indsætter et nøgle-værdi-par i hash-kortet. Hvis værdien allerede findes i hash-kortet, skal du opdatere værdien.
- get_val(nøgle): Returnerer den værdi, som den angivne nøgle er knyttet til, eller Ingen post fundet, hvis dette kort ikke indeholder nogen tilknytning til nøglen.
- delete_val(nøgle): Fjerner kortlægningen for den specifikke nøgle, hvis hashkortet indeholder tilknytningen til nøglen.
Nedenfor er implementeringen.
Python3
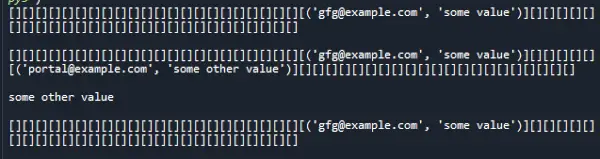
class> HashTable:> > # Create empty bucket list of given size> > def> __init__(> self> , size):> > self> .size> => size> > self> .hash_table> => self> .create_buckets()> > def> create_buckets(> self> ):> > return> [[]> for> _> in> range> (> self> .size)]> > # Insert values into hash map> > def> set_val(> self> , key, val):> > > # Get the index from the key> > # using hash function> > hashed_key> => hash> (key)> %> self> .size> > > # Get the bucket corresponding to index> > bucket> => self> .hash_table[hashed_key]> > found_key> => False> > for> index, record> in> enumerate> (bucket):> > record_key, record_val> => record> > > # check if the bucket has same key as> > # the key to be inserted> > if> record_key> => => key:> > found_key> => True> > break> > # If the bucket has same key as the key to be inserted,> > # Update the key value> > # Otherwise append the new key-value pair to the bucket> > if> found_key:> > bucket[index]> => (key, val)> > else> :> > bucket.append((key, val))> > # Return searched value with specific key> > def> get_val(> self> , key):> > > # Get the index from the key using> > # hash function> > hashed_key> => hash> (key)> %> self> .size> > > # Get the bucket corresponding to index> > bucket> => self> .hash_table[hashed_key]> > found_key> => False> > for> index, record> in> enumerate> (bucket):> > record_key, record_val> => record> > > # check if the bucket has same key as> > # the key being searched> > if> record_key> => => key:> > found_key> => True> > break> > # If the bucket has same key as the key being searched,> > # Return the value found> > # Otherwise indicate there was no record found> > if> found_key:> > return> record_val> > else> :> > return> 'No record found'> > # Remove a value with specific key> > def> delete_val(> self> , key):> > > # Get the index from the key using> > # hash function> > hashed_key> => hash> (key)> %> self> .size> > > # Get the bucket corresponding to index> > bucket> => self> .hash_table[hashed_key]> > found_key> => False> > for> index, record> in> enumerate> (bucket):> > record_key, record_val> => record> > > # check if the bucket has same key as> > # the key to be deleted> > if> record_key> => => key:> > found_key> => True> > break> > if> found_key:> > bucket.pop(index)> > return> > # To print the items of hash map> > def> __str__(> self> ):> > return> ''.join(> str> (item)> for> item> in> self> .hash_table)> hash_table> => HashTable(> 50> )> # insert some values> hash_table.set_val(> '[email protected]'> ,> 'some value'> )> print> (hash_table)> print> ()> hash_table.set_val(> '[email protected]'> ,> 'some other value'> )> print> (hash_table)> print> ()> # search/access a record with key> print> (hash_table.get_val(> '[email protected]'> ))> print> ()> # delete or remove a value> hash_table.delete_val(> '[email protected]'> )> print> (hash_table)> |
Produktion:

Tidskompleksitet:
Hukommelsesindeksadgang tager konstant tid, og hashing tager konstant tid. Derfor er søgekompleksiteten af et hash-kort også konstant tid, det vil sige O(1).
Fordele ved HashMaps
● Hurtig tilfældig hukommelsesadgang via hash-funktioner
● Kan bruge negative og ikke-integrale værdier til at få adgang til værdierne.
● Nøgler kan gemmes i sorteret rækkefølge og kan derfor nemt gentages over kortene.
Ulemper ved HashMaps
● Kollisioner kan forårsage store straffe og kan sprænge tidskompleksiteten til lineær.
● Når antallet af nøgler er stort, forårsager en enkelt hash-funktion ofte kollisioner.
Anvendelser af HashMaps
● Disse har applikationer i implementeringer af Cache, hvor hukommelsesplaceringer er kortlagt til små sæt.
● De bruges til at indeksere tupler i databasestyringssystemer.
● De bruges også i algoritmer som Rabin Karp-mønstermatchning