Dataanalyse med Python
I denne artikel vil vi diskutere, hvordan man laver dataanalyse med Python. Vi vil diskutere alle former for dataanalyse, dvs. at analysere numeriske data med NumPy, tabeldata med Pandas, datavisualisering Matplotlib og Exploratory dataanalyse.
Dataanalyse med Python
Dataanalyse er teknikken til at indsamle, transformere og organisere data for at foretage fremtidige forudsigelser og informerede datadrevne beslutninger. Det hjælper også med at finde mulige løsninger på et forretningsproblem. Der er seks trin til dataanalyse. De er:
- Spørg eller specificer datakrav
- Forbered eller indsamle data
- Rengør og bearbejd
- Analysere
- Del
- Handle eller berette
Dataanalyse med Python
Bemærk: For at vide mere om disse trin henvises til vores NumPy er en array-behandlingspakke i Python og giver et højtydende multidimensionalt array-objekt og værktøjer til at arbejde med disse arrays. Det er den grundlæggende pakke til videnskabelig databehandling med Python.
Arrays i NumPy
NumPy Array er en tabel med elementer (normalt tal), alle af de samme typer, indekseret med en tupel af positive heltal. I Numpy kaldes antallet af dimensioner af arrayet rækken af arrayet. En tuple af heltal, der angiver størrelsen af arrayet langs hver dimension, er kendt som formen på arrayet.
Oprettelse af NumPy Array
NumPy-arrays kan oprettes på flere måder med forskellige rækker. Det kan også oprettes ved brug af forskellige datatyper som lister, tupler osv. Typen af det resulterende array udledes af typen af elementer i sekvenserne. NumPy tilbyder flere funktioner til at skabe arrays med indledende pladsholderindhold. Disse minimerer nødvendigheden af at dyrke arrays, en dyr operation.
Opret Array ved hjælp af numpy.empty(shape, dtype=float, order='C')
Python3import numpy as np b = np.empty(2, dtype = int) print('Matrix b :
', b) a = np.empty([2, 2], dtype = int) print('
Matrix a :
', a) c = np.empty([3, 3]) print('
Matrix c :
', c) Produktion:

Tøm Matrix ved hjælp af pandaer
Opret Array ved hjælp af numpy.zeros(form, dtype = Ingen, rækkefølge = 'C')
Python3import numpy as np b = np.zeros(2, dtype = int) print('Matrix b :
', b) a = np.zeros([2, 2], dtype = int) print('
Matrix a :
', a) c = np.zeros([3, 3]) print('
Matrix c :
', c) Produktion:
Matrix b : [0 0] Matrix a : [[0 0] [0 0]] Matrix c : [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]
Operationer på Numpy Arrays
Aritmetiske operationer
- Tilføjelse:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing addition using arithmetic operator add_ans = a+b print(add_ans) # Performing addition using numpy function add_ans = np.add(a, b) print(add_ans) # The same functions and operations can be used for # multiple matrices c = np.array([1, 2, 3, 4]) add_ans = a+b+c print(add_ans) add_ans = np.add(a, b, c) print(add_ans)
Produktion:
[ 7 77 23 130] [ 7 77 23 130] [ 8 79 26 134] [ 7 77 23 130]
- Subtraktion:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing subtraction using arithmetic operator sub_ans = a-b print(sub_ans) # Performing subtraction using numpy function sub_ans = np.subtract(a, b) print(sub_ans)
Produktion:
[ 3 67 3 70] [ 3 67 3 70]
- Multiplikation:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing multiplication using arithmetic # operator mul_ans = a*b print(mul_ans) # Performing multiplication using numpy function mul_ans = np.multiply(a, b) print(mul_ans)
Produktion:
[ 10 360 130 3000] [ 10 360 130 3000]
- Division:
import numpy as np # Defining both the matrices a = np.array([5, 72, 13, 100]) b = np.array([2, 5, 10, 30]) # Performing division using arithmetic operators div_ans = a/b print(div_ans) # Performing division using numpy functions div_ans = np.divide(a, b) print(div_ans)
Produktion:
[ 2.5 14.4 1.3 3.33333333] [ 2.5 14.4 1.3 3.33333333]
For mere information, se vores NumPy – Selvstudie om aritmetiske operationer
NumPy Array-indeksering
Indeksering kan gøres i NumPy ved at bruge et array som et indeks. I tilfælde af udsnittet returneres en visning eller lavvandet kopi af arrayet, men i indeksarrayet returneres en kopi af det originale array. Numpy-arrays kan indekseres med andre arrays eller enhver anden sekvens med undtagelse af tupler. Det sidste element indekseres med -1 næstsidst med -2 og så videre.
Python NumPy Array-indeksering
Python3# Python program to demonstrate # the use of index arrays. import numpy as np # Create a sequence of integers from # 10 to 1 with a step of -2 a = np.arange(10, 1, -2) print('
A sequential array with a negative step:
',a) # Indexes are specified inside the np.array method. newarr = a[np.array([3, 1, 2 ])] print('
Elements at these indices are:
',newarr) Produktion:
A sequential array with a negative step: [10 8 6 4 2] Elements at these indices are: [4 8 6]
NumPy Array Slicing
Overvej syntaksen x[obj], hvor x er arrayet og obj er indekset. Skiveobjektet er indekset i tilfælde af grundlæggende udskæring . Grundlæggende udskæring sker, når obj er:
- et udsnitsobjekt, der har formen start: stop: trin
- et heltal
- eller en tuple af skiveobjekter og heltal
Alle arrays genereret af grundlæggende udskæring er altid visningen i det originale array.
Python3# Python program for basic slicing. import numpy as np # Arrange elements from 0 to 19 a = np.arange(20) print('
Array is:
',a) # a[start:stop:step] print('
a[-8:17:1] = ',a[-8:17:1]) # The : operator means all elements till the end. print('
a[10:] = ',a[10:]) Produktion:
Array is: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] a[-8:17:1] = [12 13 14 15 16] a[10:] = [10 11 12 13 14 15 16 17 18 19]
Ellipsis kan også bruges sammen med grundlæggende udskæring. Ellipsis (…) er antallet af : objekter, der er nødvendige for at lave en udvælgelses-tupel af samme længde som dimensionerne af arrayet.
Python3# Python program for indexing using basic slicing with ellipsis import numpy as np # A 3 dimensional array. b = np.array([[[1, 2, 3],[4, 5, 6]], [[7, 8, 9],[10, 11, 12]]]) print(b[...,1]) #Equivalent to b[: ,: ,1 ]
Produktion:
[[ 2 5] [ 8 11]]
NumPy Array Broadcasting
Begrebet udsendelse henviser til, hvordan numpy behandler arrays med forskellige dimensioner under aritmetiske operationer, som fører til visse begrænsninger, det mindre array udsendes på tværs af det større array, så de har kompatible former.
Lad os antage, at vi har et stort datasæt, hvert datum er en liste over parametre. I Numpy har vi et 2-D-array, hvor hver række er et datum, og antallet af rækker er størrelsen af datasættet. Antag, at vi ønsker at anvende en form for skalering på alle disse data, hver parameter får sin egen skaleringsfaktor eller sig, at hver parameter multipliceres med en eller anden faktor.
Bare for at have en klar forståelse, lad os tælle kalorier i fødevarer ved hjælp af en makronæringsstofnedbrydning. Groft sagt er de kalorieholdige dele af mad lavet af fedt (9 kalorier pr. gram), protein (4 CPG) og kulhydrater (4 CPG). Så hvis vi lister nogle fødevarer (vores data), og for hver fødevareliste dens makronæringsstofnedbrydning (parametre), kan vi derefter gange hvert næringsstof med dets kalorieværdi (anvend skalering) for at beregne kaloriefordelingen af hver fødevare.

Med denne transformation kan vi nu beregne alle slags nyttige oplysninger. For eksempel, hvad er det samlede antal kalorier til stede i noget mad eller, givet en opdeling af min aftensmad, ved, hvor mange kalorier jeg fik fra protein og så videre.
Lad os se en naiv måde at producere denne beregning på med Numpy:
Python3import numpy as np macros = np.array([ [0.8, 2.9, 3.9], [52.4, 23.6, 36.5], [55.2, 31.7, 23.9], [14.4, 11, 4.9] ]) # Create a new array filled with zeros, # of the same shape as macros. result = np.zeros_like(macros) cal_per_macro = np.array([3, 3, 8]) # Now multiply each row of macros by # cal_per_macro. In Numpy, `*` is # element-wise multiplication between two arrays. for i in range(macros.shape[0]): result[i, :] = macros[i, :] * cal_per_macro result
Produktion:
array([[ 2.4, 8.7, 31.2], [157.2, 70.8, 292. ], [165.6, 95.1, 191.2], [ 43.2, 33. , 39.2]])
Udsendelsesregler: Udsendelse af to arrays sammen følger disse regler:
- Hvis arrayerne ikke har den samme rangorden, skal du sætte formen på den lavere rangliste med 1'ere, indtil begge figurer har samme længde.
- De to arrays er kompatible i en dimension, hvis de har samme størrelse i dimensionen, eller hvis et af arrays har størrelse 1 i den dimension.
- Arrays kan udsendes sammen, hvis de er kompatible med alle dimensioner.
- Efter udsendelse opfører hvert array sig, som om det havde en form svarende til det elementmæssige maksimum af former for de to input-arrays.
- I enhver dimension, hvor et array havde en størrelse på 1, og det andet array havde en størrelse større end 1, opfører det første array sig, som om det var kopieret langs denne dimension.
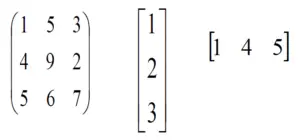
import numpy as np v = np.array([12, 24, 36]) w = np.array([45, 55]) # To compute an outer product we first # reshape v to a column vector of shape 3x1 # then broadcast it against w to yield an output # of shape 3x2 which is the outer product of v and w print(np.reshape(v, (3, 1)) * w) X = np.array([[12, 22, 33], [45, 55, 66]]) # x has shape 2x3 and v has shape (3, ) # so they broadcast to 2x3, print(X + v) # Add a vector to each column of a matrix X has # shape 2x3 and w has shape (2, ) If we transpose X # then it has shape 3x2 and can be broadcast against w # to yield a result of shape 3x2. # Transposing this yields the final result # of shape 2x3 which is the matrix. print((X.T + w).T) # Another solution is to reshape w to be a column # vector of shape 2X1 we can then broadcast it # directly against X to produce the same output. print(X + np.reshape(w, (2, 1))) # Multiply a matrix by a constant, X has shape 2x3. # Numpy treats scalars as arrays of shape(); # these can be broadcast together to shape 2x3. print(X * 2)
Produktion:
[[ 540 660] [1080 1320] [1620 1980]] [[ 24 46 69] [ 57 79 102]] [[ 57 67 78] [100 110 121]] [[ 57 67 78] [100 110 121]] [[ 24 44 66] [ 90 110 132]]
Bemærk: For mere information, se vores Python NumPy Tutorial .
Analyse af data ved hjælp af pandaer
Python Pandas Bruges til relationelle eller mærkede data og giver forskellige datastrukturer til at manipulere sådanne data og tidsserier. Dette bibliotek er bygget oven på NumPy-biblioteket. Dette modul importeres generelt som:
import pandas as pd
Her omtales pd som et alias til pandaerne. Det er dog ikke nødvendigt at importere biblioteket ved hjælp af aliaset, det hjælper bare med at skrive mindre mængdekode hver gang en metode eller egenskab kaldes. Pandaer leverer generelt to datastrukturer til at manipulere data, de er:
- Serie
- Dataramme
Serie:
Panda-serien er et endimensionelt mærket array, der er i stand til at indeholde data af enhver type (heltal, streng, float, pythonobjekter osv.). Aksemærkaterne kaldes tilsammen indekser. Pandas-serien er intet andet end en spalte i et excel-ark. Etiketter behøver ikke være unikke, men skal være en hashbar type. Objektet understøtter både heltals- og etiketbaseret indeksering og giver et væld af metoder til at udføre operationer, der involverer indekset.
Panda-serien
Det kan oprettes ved hjælp af Series()-funktionen ved at indlæse datasættet fra det eksisterende lager som SQL, Database, CSV-filer, Excel-filer osv., eller fra datastrukturer som lister, ordbøger osv.
Python Pandas Creating Series
Python3import pandas as pd import numpy as np # Creating empty series ser = pd.Series() print(ser) # simple array data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser)
Produktion:

pandas serie
Dataramme:
Pandas DataFrame er en todimensionel størrelse-muterbar, potentielt heterogen tabelformet datastruktur med mærkede akser (rækker og kolonner). En dataramme er en todimensionel datastruktur, dvs. data er justeret i tabelform i rækker og kolonner. Pandas DataFrame består af tre hovedkomponenter, data, rækker og kolonner.
Pandas dataramme
Det kan oprettes ved hjælp af Dataframe() metoden og ligesom en serie kan det også være fra forskellige filtyper og datastrukturer.
Python Pandas skaber dataramme
Python3import pandas as pd # Calling DataFrame constructor df = pd.DataFrame() print(df) # list of strings lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) df
Produktion:

Oprettelse af dataramme fra python-liste
Oprettelse af dataramme fra CSV
Vi kan oprette en dataramme fra CSV'en filer ved hjælp af read_csv() fungere.
Python Pandas læste CSV
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # Printing top 5 rows df.head() Produktion:

leder af en dataramme
Filtrering af DataFrame
Pandaer dataframe.filter() funktionen bruges til at undersætte rækker eller kolonner af dataramme i henhold til etiketter i det angivne indeks. Bemærk, at denne rutine ikke filtrerer en dataramme på dens indhold. Filteret anvendes på indeksets etiketter.
Python Pandas filterdataramme
Python3import pandas as pd # Reading the CSV file df = pd.read_csv('Iris.csv') # applying filter function df.filter(['Species', 'SepalLengthCm', 'SepalLengthCm']).head() Produktion:

Anvender filter på datasæt
Sortering af DataFrame
For at sortere datarammen i pandaer skal funktionen sort_værdier() anvendes. Pandas sort_values() kan sortere datarammen i stigende eller faldende rækkefølge.
Python Pandas sortering af dataramme i stigende rækkefølge
Produktion:

Sorteret datasæt baseret på en kolonneværdi
Pandas GroupBy
Groupby er et ret simpelt koncept. Vi kan oprette en gruppering af kategorier og anvende en funktion på kategorierne. I rigtige data science-projekter vil du beskæftige dig med store mængder data og prøve ting igen og igen, så for effektiviteten bruger vi Groupby-konceptet. Groupby refererer hovedsageligt til en proces, der involverer et eller flere af følgende trin, de er:
- Opdeling: Det er en proces, hvor vi opdeler data i grupper ved at anvende nogle betingelser på datasæt.
- Ansøger: Det er en proces, hvor vi anvender en funktion til hver gruppe selvstændigt.
- Ved at kombinere: Det er en proces, hvor vi kombinerer forskellige datasæt efter at have anvendt groupby og resultater til en datastruktur.
Følgende billede vil hjælpe med at forstå processen involveret i Groupby-konceptet.
1. Gruppér de unikke værdier fra kolonnen Team
Pandas Groupby metode
2. Nu er der en spand til hver gruppe
3. Smid de andre data i bøttene

4. Anvend en funktion på vægtkolonnen på hver spand.
Anvendelse af funktion på vægtkolonnen i hver kolonne
Python Pandas GroupBy
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) print('Original Dataframe') display(df) # applying groupby() function to # group the data on Name value. gk = df.groupby('Name') # Let's print the first entries # in all the groups formed. print('After Creating Groups') gk.first() Produktion:

pandas gruppeby
Anvendelse af funktion til gruppe:
Efter at have opdelt en data i en gruppe, anvender vi en funktion til hver gruppe for at gøre, at vi udfører nogle operationer, de er:
- Aggregation: Det er en proces, hvor vi beregner en sammenfattende statistik (eller statistik) om hver gruppe. For eksempel, Beregn gruppesummer eller middel
- Transformation: Det er en proces, hvor vi udfører nogle gruppespecifikke beregninger og returnerer en like-indekseret. For eksempel udfyldning af NA'er inden for grupper med en værdi afledt af hver gruppe
- Filtrering: Det er en proces, hvor vi kasserer nogle grupper, ifølge en gruppevis beregning, der evaluerer Sandt eller Falsk. For eksempel frafiltrering af data baseret på gruppesum eller gennemsnit
Panda Aggregation
Aggregation er en proces, hvor vi beregner en opsummerende statistik om hver gruppe. Den aggregerede funktion returnerer en enkelt aggregeret værdi for hver gruppe. Efter at have opdelt data i grupper ved hjælp af groupby-funktion, kan flere aggregeringsoperationer udføres på de grupperede data.
Python Pandas Aggregation
Python3# importing pandas module import pandas as pd # importing numpy as np import numpy as np # Define a dictionary containing employee data data1 = {'Name': ['Jai', 'Anuj', 'Jai', 'Princi', 'Gaurav', 'Anuj', 'Princi', 'Abhi'], 'Age': [27, 24, 22, 32, 33, 36, 27, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj', 'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd', 'B.Tech', 'B.com', 'Msc', 'MA']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # performing aggregation using # aggregate method grp1 = df.groupby('Name') grp1.aggregate(np.sum) Produktion:

Brug af sum aggregat funktion på datasæt
Sammenkædning af DataFrame
For at sammenkæde datarammen bruger vi concat() funktion, som hjælper med at sammenkæde datarammen. Denne funktion udfører alt det tunge løft ved at udføre sammenkædningsoperationer sammen med en akse af Pandas-objekter, mens den udfører valgfri sætlogik (forening eller skæring) af indekserne (hvis nogen) på de andre akser.
Python Pandas Sammenkædning af dataramme
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # combining series and dataframe res = pd.concat([df, df1], axis=1) res Produktion:

Sammenlægning af DataFrame
Når vi skal kombinere meget store DataFrames, tjener joinforbindelser som en effektiv måde at udføre disse operationer hurtigt. Joins kan kun udføres på to DataFrames ad gangen, angivet som venstre og højre tabeller. Nøglen er den fælles kolonne, som de to DataFrames vil blive forbundet på. Det er en god praksis at bruge nøgler, der har unikke værdier i hele kolonnen for at undgå utilsigtet duplikering af rækkeværdier. Pandaer har en enkelt funktion, fusionere() , som indgangspunkt for alle standarddatabasesammenføjningsoperationer mellem DataFrame-objekter.
Der er fire grundlæggende måder at håndtere joinforbindelsen på (indre, venstre, højre og ydre), afhængigt af hvilke rækker der skal beholde deres data.

Python Pandas Merge Dataframe
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # Define a dictionary containing employee data data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2) display(df, df1) # using .merge() function res = pd.merge(df, df1, on='key') res Produktion:

Sammenkædning af to datasæt
Deltager i DataFrame
For at tilslutte os datarammen bruger vi .tilslutte() funktion denne funktion bruges til at kombinere kolonnerne af to potentielt forskelligt indekserede DataFrames til en enkelt resultat DataFrame.
Python Pandas Join Dataframe
Python3# importing pandas module import pandas as pd # Define a dictionary containing employee data data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]} # Define a dictionary containing employee data data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # Convert the dictionary into DataFrame df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3']) # Convert the dictionary into DataFrame df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) display(df, df1) # joining dataframe res = df.join(df1) res Produktion:

Sammenføjning af to datasæt
For mere information, se vores Pandaer, der fusionerer, sammenføjer og sammenkæder tutorial
For en komplet vejledning om pandaer henvises til vores Tutorial for pandaer .
Visualisering med Matplotlib
Matplotlib er let at bruge og et fantastisk visualiseringsbibliotek i Python. Den er bygget på NumPy-arrays og designet til at arbejde med den bredere SciPy-stak og består af flere plots som linje, streg, scatter, histogram osv.
Pyplot
Pyplot er et Matplotlib-modul, der giver en MATLAB-lignende grænseflade. Pyplot giver funktioner, der interagerer med figuren, dvs. skaber en figur, dekorerer plottet med etiketter og opretter et plotteområde i en figur.
Python3# Python program to show pyplot module import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4], [1, 4, 9, 16]) plt.axis([0, 6, 0, 20]) plt.show()
Produktion:

Søjlediagram
EN bar grund eller søjlediagram er en graf, der repræsenterer kategorien af data med rektangulære søjler med længder og højder, der er proportional med de værdier, de repræsenterer. Søjleplottene kan plottes vandret eller lodret. Et søjlediagram beskriver sammenligningerne mellem de diskrete kategorier. Det kan oprettes ved hjælp af bar() metoden.
Python Matplotlib søjlediagram
Her vil vi kun bruge iris-datasættet
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') # This will plot a simple bar chart plt.bar(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Iris Dataset') # Adding the legends plt.legend(['bar']) plt.show() Produktion:

Søjlediagram ved hjælp af matplotlib-bibliotek
Histogrammer
EN histogram bruges grundlæggende til at repræsentere data i form af nogle grupper. Det er en type søjleplot, hvor X-aksen repræsenterer bin-områderne, mens Y-aksen giver information om frekvens. For at oprette et histogram er det første trin at oprette en bin med intervallerne, derefter fordele hele intervallet af værdierne i en række intervaller og tælle de værdier, der falder ind i hvert af intervallerne. Bins er tydeligt identificeret som konsekutive, ikke-overlappende intervaller af variable. Det hist() funktion bruges til at beregne og skabe et histogram af x.
Python Matplotlib Histogram
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.hist(df['SepalLengthCm']) # Title to the plot plt.title('Histogram') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Produktion:

Histplot ved hjælp af matplotlib-bibliotek
Scatter Plot
Scatterplot bruges til at observere forholdet mellem variabler og bruger prikker til at repræsentere forholdet mellem dem. Det sprede() metoden i matplotlib-biblioteket bruges til at tegne et scatterplot.
Python Matplotlib Scatter Plot
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.scatter(df['Species'], df['SepalLengthCm']) # Title to the plot plt.title('Scatter Plot') # Adding the legends plt.legend(['SepalLengthCm']) plt.show() Produktion:

Scatter-plot ved hjælp af matplotlib-bibliotek
Box Plot
EN boxplot ,Korrelation også kendt som et boks- og whiskerplot. Det er en meget god visuel repræsentation, når det kommer til at måle datafordelingen. Plot tydeligt medianværdierne, outliers og kvartilerne. Forståelse af datadistribution er en anden vigtig faktor, som fører til bedre modelbygning. Hvis data har outliers, er boksplot en anbefalet måde at identificere dem og tage nødvendige handlinger. Boksen og whiskers-diagrammet viser, hvordan data er spredt ud. Fem oplysninger er generelt inkluderet i diagrammet
- Minimum er vist yderst til venstre i diagrammet, i slutningen af venstre 'whisker'
- Første kvartil, Q1, er yderst til venstre i boksen (venstre knurhår)
- Medianen vises som en linje i midten af boksen
- Tredje kvartil, Q3, vist yderst til højre i boksen (højre knurhår)
- Maksimum er yderst til højre i boksen
Repræsentation af boksplot

Interkvartilinterval

Illustrerende boksplot
Python Matplotlib Box Plot
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.boxplot(df['SepalWidthCm']) # Title to the plot plt.title('Box Plot') # Adding the legends plt.legend(['SepalWidthCm']) plt.show() Produktion:

Boxplot ved hjælp af matplotlib-bibliotek
Korrelation Heatmaps
Et 2-D Heatmap er et datavisualiseringsværktøj, der hjælper med at repræsentere størrelsen af fænomenet i form af farver. Et korrelationsvarmekort er et varmekort, der viser en 2D-korrelationsmatrix mellem to diskrete dimensioner, ved hjælp af farvede celler til at repræsentere data fra normalt en monokromatisk skala. Værdierne for den første dimension vises som rækkerne i tabellen, mens den anden dimension er en kolonne. Cellens farve er proportional med antallet af målinger, der matcher dimensionsværdien. Dette gør korrelationsvarmekort ideelle til dataanalyse, da det gør mønstre let læsbare og fremhæver forskellene og variationen i de samme data. Et korrelationsvarmekort er ligesom et almindeligt varmekort assisteret af en farvelinje, der gør data let læselige og forståelige.
Bemærk: Dataene her skal sendes med corr()-metoden for at generere et korrelationsvarmekort. Corr() eliminerer også selv kolonner, der ikke vil være til nogen nytte, mens der genereres et korrelationsvarmekort, og vælger dem, der kan bruges.
Python Matplotlib Correlation Heatmap
Python3import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('Iris.csv') plt.imshow(df.corr() , cmap = 'autumn' , interpolation = 'nearest' ) plt.title('Heat Map') plt.show() Produktion:

Heatmap ved hjælp af matplotlib-bibliotek
For mere information om datavisualisering henvises til vores nedenstående tutorials –
- Bemærk: Vi vil bruge Iris Dataset.
Få information om datasættet
Vi vil bruge formparameteren til at få datasættets form.
Form af dataramme
Python3df.shapeProduktion:
(150, 6)Vi kan se, at datarammen indeholder 6 kolonner og 150 rækker.
Bemærk: Vi vil bruge Iris Dataset.
Få information om datasættet
Lad os nu også kolonnerne og deres datatyper. Til dette vil vi bruge info() metode.
Information om Datasæt
Python3df.info()Produktion:

oplysninger om datasættet
Vi kan se, at kun én kolonne har kategoriske data, og alle de andre kolonner er af den numeriske type med ikke-Null-indtastninger.
Lad os få en hurtig statistisk oversigt over datasættet ved hjælp af beskrive() metode. Funktionen describe() anvender grundlæggende statistiske beregninger på datasættet som ekstreme værdier, antal datapunkters standardafvigelse osv. Enhver manglende værdi eller NaN-værdi springes automatisk over. describe() funktion giver et godt billede af fordelingen af data.
Beskrivelse af datasæt
Python3df.describe()Produktion:

Beskrivelse af datasættet
Vi kan se antallet af hver kolonne sammen med deres middelværdi, standardafvigelse, minimums- og maksimumværdier.
Kontrol af manglende værdier
Vi vil kontrollere, om vores data indeholder manglende værdier eller ej. Manglende værdier kan forekomme, når der ikke er angivet information for en eller flere varer eller for en hel enhed. Vi vil bruge isnull() metode.
python-kode for manglende værdi
Python3df.isnull().sum()Produktion:

Manglende værdier i datasættet
Vi kan se, at ingen kolonne har nogen manglende værdi.
Kontrol af dubletter
Lad os se, om vores datasæt indeholder nogen dubletter eller ej. Pandaer drop_duplicates() metode hjælper med at fjerne dubletter fra datarammen.
Pandas funktion til manglende værdier
Python3data = df.drop_duplicates(subset ='Species',) dataProduktion:

Slet dubletværdi i datasættet
Vi kan se, at der kun er tre unikke arter. Lad os se, om datasættet er afbalanceret eller ej, dvs. alle arterne indeholder lige mange rækker eller ej. Vi vil bruge Series.value_counts() fungere. Denne funktion returnerer en serie, der indeholder antallet af unikke værdier.
Python-kode for værdiantal i kolonnen
Python3df.value_counts('Species')Produktion:

værdiantal i datasættet
Vi kan se, at alle arterne indeholder lige mange rækker, så vi bør ikke slette nogen poster.
Relation mellem variabler
Vi vil se sammenhængen mellem bægerbladslængden og bægerbladsbredden og også mellem kronbladslængden og kronbladsbredden.
Sammenligning af bægerbladslængde og bægerbladsbredde
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Produktion:

Scatter-plot ved hjælp af matplotlib-bibliotek
Fra ovenstående plot kan vi udlede, at -
- Arten Setosa har mindre bægerbladslængder, men større bægerbladsbredder.
- Versicolor Species ligger i midten af de to andre arter med hensyn til bægerbladslængde og -bredde
- Arten Virginica har større bægerbladslængder, men mindre bægerbladsbredder.
Sammenligning af kronbladslængde og kronbladsbredde
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', data=df, ) # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()Produktion:

sactter plot kronbladslængde
Fra ovenstående plot kan vi udlede, at -
- Arten Setosa har mindre kronbladslængder og -bredder.
- Versicolor Species ligger i midten af de to andre arter med hensyn til kronbladslængde og -bredde
- Arten Virginica har de største kronbladslængder og -bredder.
Lad os plotte alle kolonnens relationer ved hjælp af et parplot. Det kan bruges til multivariat analyse.
Python-kode til parplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.pairplot(df.drop(['Id'], axis = 1), hue='Species', height=2)Produktion:
Parplot for datasættet
Vi kan se mange typer forhold fra dette plot, såsom arten Seotsa har den mindste kronbladsbredde og -længde. Den har også den mindste bægerbladslængde, men større bægerbladsbredder. Sådan information kan indsamles om enhver anden art.
Håndtering af korrelation
Pandaer dataframe.corr() bruges til at finde den parvise korrelation af alle kolonner i datarammen. Eventuelle NA-værdier ekskluderes automatisk. Alle ikke-numeriske datatypekolonner i datarammen ignoreres.
Eksempel:
Python3data.corr(method='pearson')Produktion:

korrelation mellem kolonner i datasættet
Varmekort
Varmekortet er en datavisualiseringsteknik, der bruges til at analysere datasættet som farver i to dimensioner. Grundlæggende viser det en sammenhæng mellem alle numeriske variable i datasættet. I enklere termer kan vi plotte den ovenfor fundne korrelation ved hjælp af varmekortene.
python-kode til heatmap
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.heatmap(df.corr(method='pearson').drop( ['Id'], axis=1).drop(['Id'], axis=0), annot = True); plt.show()Produktion:

Heatmap for korrelation i datasættet
Fra ovenstående graf kan vi se, at -
- Kronbladsbredde og kronbladslængde har høje korrelationer.
- Kronbladslængde og bægerbladsbredde har gode korrelationer.
- Kronbladsbredde og bægerbladslængde har gode korrelationer.
Håndtering af outliers
En Outlier er et dataelement/objekt, der afviger væsentligt fra resten af de (såkaldte normale) objekter. De kan være forårsaget af måle- eller udførelsesfejl. Analysen for outlier-detektion omtales som outlier mining. Der er mange måder at opdage outliers på, og fjernelsesprocessen er den samme dataramme som at fjerne et dataelement fra pandaens dataramme.
Lad os overveje iris-datasættet og lad os plotte boxplotten for SepalWidthCm-kolonnen.
python-kode til Boxplot
Python3# importing packages import seaborn as sns import matplotlib.pyplot as plt # Load the dataset df = pd.read_csv('Iris.csv') sns.boxplot(x='SepalWidthCm', data=df)Produktion:

Boksplot til sepalwidth kolonne
I ovenstående graf fungerer værdierne over 4 og under 2 som outliers.
Fjernelse af outliers
For at fjerne outlieren skal man følge den samme proces med at fjerne en post fra datasættet ved at bruge dens nøjagtige position i datasættet, fordi i alle ovenstående metoder til at detektere outliers er slutresultatet listen over alle de dataelementer, der opfylder outlier-definitionen efter den anvendte metode.
Vi vil opdage outliers ved hjælp af IQR og så fjerner vi dem. Vi vil også tegne boxplotten for at se, om afvigelserne er fjernet eller ej.
Python3# Importing import sklearn from sklearn.datasets import load_boston import pandas as pd import seaborn as sns # Load the dataset df = pd.read_csv('Iris.csv') # IQR Q1 = np.percentile(df['SepalWidthCm'], 25, interpolation = 'midpoint') Q3 = np.percentile(df['SepalWidthCm'], 75, interpolation = 'midpoint') IQR = Q3 - Q1 print('Old Shape: ', df.shape) # Upper bound upper = np.where(df['SepalWidthCm']>= (Q3+1.5*IQR)) # Nedre grænse nedre = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR)) # Removing the Outliers df.drop(upper[0], inplace = True) df.drop(lower[0], inplace = True) print('New Shape: ', df.shape) sns.boxplot(x='SepalWidthCm', data=df)Produktion:

boxplot ved hjælp af Seaborn-biblioteket
For mere information om EDA, se vores nedenstående tutorials –