Jednoduchý vícevláknový správce stahování v Pythonu
A Správce stahování je v podstatě počítačový program určený ke stahování samostatných souborů z internetu. Zde vytvoříme jednoduchý Download Manager s pomocí vláken v Pythonu. Pomocí multi-threadingu lze soubor stáhnout ve formě bloků současně z různých vláken. Abychom to mohli implementovat, vytvoříme jednoduchý nástroj příkazového řádku, který přijme adresu URL souboru a poté jej stáhne.
Předpoklady: Počítač Windows s nainstalovaným Pythonem.
Nastavení
Stáhněte si níže uvedené balíčky z příkazového řádku.
1. Click package: Click je balíček Pythonu pro vytváření krásných rozhraní příkazového řádku s co nejmenším potřebným kódem. Je to sada pro tvorbu rozhraní příkazového řádku.
klikněte na instalaci pip
2. Balíček požadavků: V tomto nástroji stáhneme soubor na základě URL (adres HTTP). Requests je HTTP knihovna napsaná v Pythonu, která vám umožňuje odesílat HTTP požadavky. Pomocí jednoduchých slovníků Pythonu můžete přidávat záhlaví datových souborů s více částmi a parametry a přistupovat k datům odpovědí stejným způsobem.
požadavky na instalaci pip
3. Threading package: Pro práci s vlákny potřebujeme Threading package.
pip install závitování
Implementace
Poznámka:
Program byl rozdělen do částí, aby byl srozumitelný. Ujistěte se, že vám při běhu programu nechybí žádná část kódu.
Krok 1: Importujte požadované balíčky
Tyto balíčky poskytují potřebné nástroje k tomu, aby webové požadavky zpracovávaly vstupy z příkazového řádku a vytvářely vlákna.
Python import click import requests import threading
Krok 2: Vytvořte funkci Handler
Každé vlákno provede tuto funkci, aby si stáhlo svou specifickou část souboru. Tato funkce je zodpovědná za vyžádání pouze určitého rozsahu bajtů a jejich zapsání na správnou pozici v souboru.
Python def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content )
Krok 3: Definujte hlavní funkci kliknutím
Změní funkci na nástroj příkazového řádku. To definuje, jak uživatelé interagují se skriptem z příkazového řádku.
Python #Note: This code will not work on online IDE @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ):
Krok 4: Nastavte název souboru a určete velikost souboru
Potřebujeme velikost souboru k rozdělení stahování mezi vlákna a zajištění, že server podporuje stahování v rozsahu.
Python r = requests . head ( url_of_file ) file_name = name if name else url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return
Krok 5: Předběžně přidělte souborový prostor
Předběžné přidělení zajišťuje, že soubor má správnou velikost, než zapíšeme bloky do konkrétních rozsahů bajtů.
Python part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size )
Krok 6: Vytvořte vlákna
Vlákna mají přiřazeny specifické rozsahy bajtů, které se mají stahovat paralelně.
Python threads = [] for i in range ( number_of_threads ): start = part * i end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start ()
Krok 7: Připojte vlákna
Zajišťuje dokončení všech vláken před dokončením programu.
Python for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Kód:
Python import click import requests import threading def Handler ( start end url filename ): headers = { 'Range' : f 'bytes= { start } - { end } ' } r = requests . get ( url headers = headers stream = True ) with open ( filename 'r+b' ) as fp : fp . seek ( start ) fp . write ( r . content ) @click . command ( help = 'Downloads the specified file with given name using multi-threading' ) @click . option ( '--number_of_threads' default = 4 help = 'Number of threads to use' ) @click . option ( '--name' type = click . Path () help = 'Name to save the file as (with extension)' ) @click . argument ( 'url_of_file' type = str ) def download_file ( url_of_file name number_of_threads ): r = requests . head ( url_of_file ) if name : file_name = name else : file_name = url_of_file . split ( '/' )[ - 1 ] try : file_size = int ( r . headers [ 'Content-Length' ]) except : print ( 'Invalid URL or missing Content-Length header.' ) return part = file_size // number_of_threads with open ( file_name 'wb' ) as fp : fp . write ( b ' � ' * file_size ) threads = [] for i in range ( number_of_threads ): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else ( start + part - 1 ) t = threading . Thread ( target = Handler kwargs = { 'start' : start 'end' : end 'url' : url_of_file 'filename' : file_name }) threads . append ( t ) t . start () for t in threads : t . join () print ( f ' { file_name } downloaded successfully!' ) if __name__ == '__main__' : download_file ()
Jsme hotovi s kódovací částí a nyní postupujte podle níže uvedených příkazů pro spuštění souboru .py.
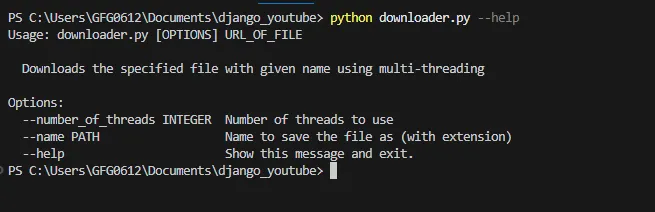
python filename.py –-helpvýstup:
python filename.py –-help
Tento příkaz ukazuje použití nástroje příkazu kliknutí a možnosti, které nástroj může přijmout. Níže je ukázkový příkaz, kde se pokoušíme stáhnout soubor obrázku jpg z adresy URL a také jsme uvedli název a počet_vláknů.
ukázkový příkaz ke stažení jpg
Poté, co vše úspěšně spustíte, budete moci vidět svůj soubor (v tomto případě flower.webp) v adresáři vaší složky, jak je znázorněno níže:
adresář
Nakonec jsme s tím úspěšně skončili a toto je jeden ze způsobů, jak v Pythonu vytvořit jednoduchý multithreaded download manager.
 python filename.py –-help
python filename.py –-help  ukázkový příkaz ke stažení jpg
ukázkový příkaz ke stažení jpg  adresář
adresář