Python SQLAlchemy – func.count s filtrem

V tomto článku se podíváme, jak provést operaci filtru s funkcí count v SQLAlchemy proti databázi PostgreSQL v pythonu
Operace počítání s filtry se provádí různými metodami s použitím různých funkcí. Takové druhy matematických operací jsou závislé na databázi. V PostgreSQL se počítání provádí pomocí funkce nazvané count() a operace filtrování se provádí pomocí filter(). V SQLAlchemy se obecné funkce jako SUM, MIN, MAX vyvolávají jako konvenční funkce SQL pomocí atributu func.
Některé běžné funkce používané v SQLAlchemy jsou count, cube, current_date, current_time, max, min, mode atd.
Používání: func.count(). func.group_by(), func.max()
Vytvoření tabulky pro demonstraci
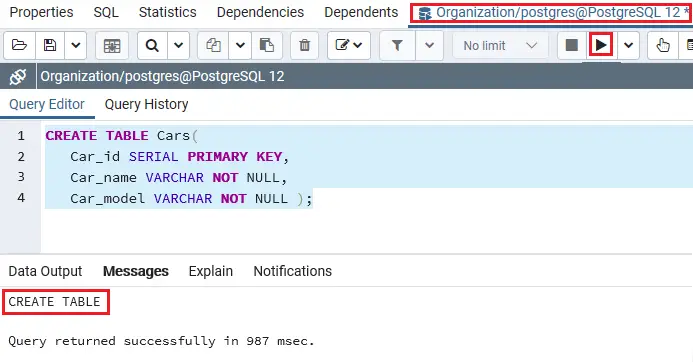
Importujte potřebné funkce z balíčku SQLAlchemy. Navažte spojení s databází PostgreSQL pomocí funkce create_engine(), jak je uvedeno níže, vytvořte tabulku nazvanou knihy se sloupci book_id a book_price. Vložte záznam do tabulek pomocí funkcí insert() a values() podle obrázku.
Python3
# import necessary packages> import> sqlalchemy> from> sqlalchemy> import> create_engine, MetaData, Table,> Column, Numeric, Integer, VARCHAR> from> sqlalchemy.engine> import> result> > # establish connections> engine> => create_engine(> > 'database+ dialect://username:password@host:port/databasename '> )> > # initialize the Metadata Object> meta> => MetaData(bind> => engine)> MetaData.reflect(meta)> > # create a table schema> books> => Table(> > 'books'> , meta,> > Column(> 'bookId'> , Integer, primary_key> => True> ),> > Column(> 'book_price'> , Numeric),> > Column(> 'genre'> , VARCHAR),> > Column(> 'book_name'> , VARCHAR)> )> > meta.create_all(engine)> # insert records into the table> statement1> => books.insert().values(bookId> => 1> , book_price> => 12.2> ,> > genre> => 'fiction'> ,> > book_name> => 'Old age'> )> statement2> => books.insert().values(bookId> => 2> , book_price> => 13.2> ,> > genre> => 'non-fiction'> ,> > book_name> => 'Saturn rings'> )> statement3> => books.insert().values(bookId> => 3> , book_price> => 121.6> ,> > genre> => 'fiction'> ,> > book_name> => 'Supernova'> )> statement4> => books.insert().values(bookId> => 4> , book_price> => 100> ,> > genre> => 'non-fiction'> ,> > book_name> => 'History of the world'> )> statement5> => books.insert().values(bookId> => 5> , book_price> => 1112.2> ,> > genre> => 'fiction'> ,> > book_name> => 'Sun city'> )> > # execute the insert records statement> engine.execute(statement1)> engine.execute(statement2)> engine.execute(statement3)> engine.execute(statement4)> engine.execute(statement5)> |
Výstup:

Ukázková tabulka
Implementace GroupBy a count v SQLAlchemy
Zápis funkce groupby má mírně odlišný postup než konvenční SQL dotaz, který je uveden níže
sqlalchemy.select([
Tablename.c.column_name,
sqlalchemy.func.count(název_tabulky.c.název_sloupce)
]).group_by(název_tabulky.c.název_sloupce).filter(hodnota název_tabulky.c.název_sloupce)
Získejte tabulku knih z objektu Metadata inicializovanou při připojování k databázi. Předejte SQL dotaz funkci execute() a získejte všechny výsledky pomocí funkce fetchall(). K iteraci výsledků použijte cyklus for.
Níže uvedený dotaz vrátí počet knih v různých žánrech, jejichž ceny jsou vyšší než Rs. 50.
Python3
# Get the `books` table from the Metadata object> BOOKS> => meta.tables[> 'books'> ]> > # SQLAlchemy Query to GROUP BY and filter function> query> => sqlalchemy.select([> > BOOKS.c.genre,> > sqlalchemy.func.count(BOOKS.c.genre)> ]).group_by(BOOKS.c.genre).> filter> (BOOKS.c.book_price>> 50.0> )> > # Fetch all the records> result> => engine.execute(query).fetchall()> > # View the records> for> record> in> result:> > print> (> '
'> , record)> |
Výstup:

Výstup funkce Počet a filtr