Normální distribuce v R
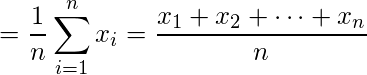
Normální distribuce je pravděpodobnostní funkce používaná ve statistice, která vypovídá o tom, jak jsou distribuovány hodnoty dat. Je to nejdůležitější funkce rozdělení pravděpodobnosti používaná ve statistice kvůli jejím výhodám v reálných scénářích. Například výška populace, velikost bot, úroveň IQ, hod kostkou a mnoho dalších. Obecně se pozoruje, že distribuce dat je normální, pokud dochází k náhodnému sběru dat z nezávislých zdrojů. Graf vytvořený po vynesení hodnoty proměnné na osu x a počtu hodnot na ose y je křivkový graf ve tvaru zvonu. Graf znamená, že vrcholový bod je průměrem souboru dat a polovina hodnot souboru dat leží na levé straně průměru a druhá polovina leží na pravé části průměru vypovídající o rozložení hodnot. Graf je symetrické rozdělení. V R jsou 4 vestavěné funkce pro generování normální distribuce:  je zlý a
je zlý a 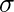 je standardní odchylka. Syntaxe:
je standardní odchylka. Syntaxe:
Výstup: 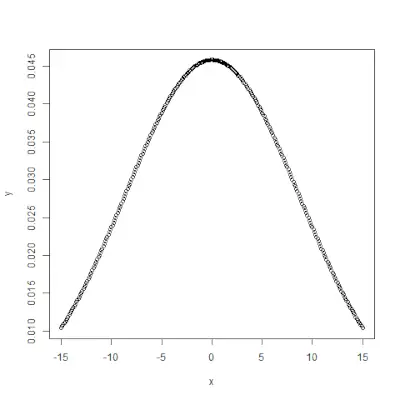
Výstup : 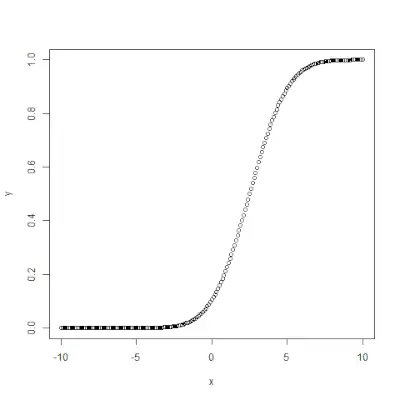
Výstup: 
Výstup : 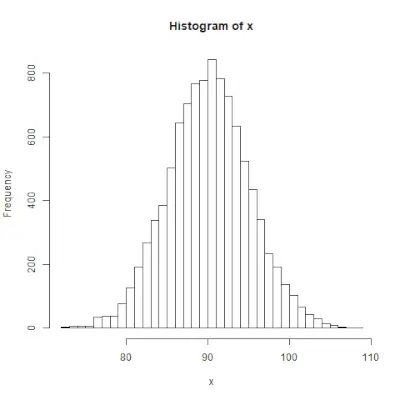
- dnorm()
dnorm(x, mean, sd)pnorm()
pnorm(x, mean, sd)qnorm()
qnorm(p, mean, sd)rnorm()
rnorm(n, mean, sd)kde,
– X představuje datovou sadu hodnot – střední (x) představuje průměr souboru dat X . Jeho výchozí hodnota je 0.– sd(x) představuje standardní odchylku souboru dat X . Jeho výchozí hodnota je 1.– n je počet pozorování. – p je vektor pravděpodobností
Funkce pro generování normálního rozdělení v R
dnorm()
dnorm()> funkce v programování R měří hustotní funkci rozdělení. Ve statistice se měří podle níže uvedeného vzorce -kde,  je zlý a
je zlý a 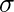 je standardní odchylka. Syntaxe:
je standardní odchylka. Syntaxe: dnorm(x, mean, sd)Příklad:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x> => seq(> -> 15> ,> 15> , by> => 0.1> )> > y> => dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(> file> => 'dnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |

pnorm()
pnorm()> funkce je kumulativní distribuční funkce, která měří pravděpodobnost, že náhodné číslo X nabývá hodnoty menší nebo rovné x, tj. ve statistice je dáno - Syntax: pnorm(x, mean, sd)Příklad:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <> -> seq(> -> 10> ,> 10> , by> => 0.1> )> > y <> -> pnorm(x, mean> => 2.5> , sd> => 2> )> > # output to be present as PNG file> png(> file> => 'pnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |

qnorm()
qnorm()> funkce je inverzní k pnorm()> funkce. Vezme hodnotu pravděpodobnosti a dá výstup, který odpovídá hodnotě pravděpodobnosti. Je to užitečné při hledání percentilů normálního rozdělení. Syntax: qnorm(p, mean, sd)Příklad:
# Create a sequence of probability values> # incrementing by 0.02.> x <> -> seq(> 0> ,> 1> , by> => 0.02> )> > y <> -> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(> file> => 'qnormExample.webp'> )> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |

rnorm()
rnorm()> Funkce v programování R se používá ke generování vektoru náhodných čísel, která jsou normálně rozdělena. Syntax: rnorm(x, mean, sd)Příklad:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <> -> rnorm(> 10000> , mean> => 90> , sd> => 5> )> > # output to be present as PNG file> png(> file> => 'rnormExample.webp'> )> > # Create the histogram with 50 bars> hist(x, breaks> => 50> )> > # Save the file.> dev.off()> |