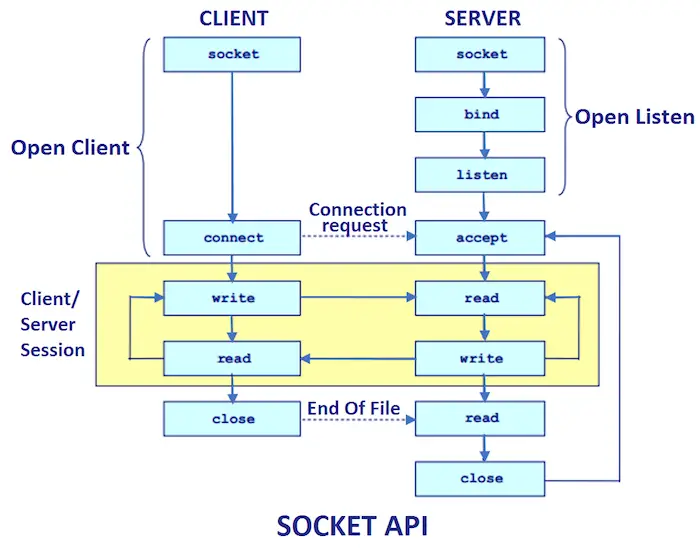
Algoritmus KMP pro vyhledávání vzorů

Daný text txt[0. . . N-1] a vzor postel[0 . . . M-1] , napište funkci vyhledávání (char pat[], char txt[]), která vypíše všechny výskyty pat[] v txt[]. Můžete to předpokládat N > M .
Příklady:
Doporučené řešení problému ProblémVstup: txt[] = TOTO JE TESTOVACÍ TEXT, pat[] = TEST
Výstup: Vzor nalezen na indexu 10Vstup: txt[] = VAŠI OTCOVÉ
pat[] = AABA
Výstup: Vzor nalezen na indexu 0, Vzor nalezen na indexu 9, Vzor nalezen na indexu 12
Příchody vzoru v textu

Probrali jsme naivní algoritmus pro vyhledávání vzorů v předchozí příspěvek . Nejhorší případ složitosti naivního algoritmu je O(m(n-m+1)). Časová složitost KMP algoritmu je v nejhorším případě O(n+m).
Vyhledávání vzorů KMP (Knuth Morris Pratt):
The Naivní algoritmus pro vyhledávání vzorů nefunguje dobře v případech, kdy vidíme mnoho shodných znaků následovaných neshodným znakem.
Příklady:
1) txt[] = AAAAAAAAAAAAAAAAAAB, pat[] = AAAAB
2) txt[] = ABABABCABABABCABABABC, pat[] = ABABAC (není nejhorší případ, ale špatný případ pro naivní)
Algoritmus porovnávání KMP využívá degenerující vlastnost (vzor se stejnými dílčími vzory, které se ve vzoru objevují více než jednou) a zlepšuje složitost nejhoršího případu. O(n+m) .
Základní myšlenka algoritmu KMP je: kdykoli zjistíme neshodu (po několika shodách), známe již některé znaky v textu dalšího okna. Tyto informace využíváme, abychom se vyhnuli shodě znaků, o kterých víme, že se stejně budou shodovat.
Přehled shod
txt = AAAAABAAABA
pat = AAAA
Porovnáváme první okno txt s stejnýtxt = AAAA OTEC
dokonce = AAAA [Počáteční pozice]
Najdeme shodu. Toto je stejné jako Naivní párování řetězců .V dalším kroku porovnáme další okno txt s stejný .
txt = ááááá ZNIČIT
dokonce = AAAA [Vzor posunut o jednu pozici]To je místo, kde KMP provádí optimalizaci oproti Naive. V tomto druhém okně porovnáváme pouze čtvrté A vzoru
se čtvrtým znakem aktuálního okna textu k rozhodnutí, zda aktuální okno odpovídá nebo ne. Protože víme
první tři znaky se stejně budou shodovat, vynechali jsme shodu prvních tří znaků.Potřebujete předběžné zpracování?
Z výše uvedeného vysvětlení vyvstává důležitá otázka, jak poznat, kolik znaků se má přeskočit. Abyste to věděli,
předem zpracujeme vzor a připravíme celočíselné pole lps[], které nám řekne počet znaků, které mají být přeskočeny
Přehled předběžného zpracování:
- Algoritmus KMP předzpracuje pat[] a vytvoří pomocnou lps[] velikosti m (stejná jako velikost vzoru), která se používá k přeskakování znaků při párování.
- název lps označuje nejdelší vlastní předponu, která je zároveň příponou. Správná předpona je předpona s celým řetězcem, který není povolen. Například předpony ABC jsou , A, AB a ABC. Správné předpony jsou , A a AB. Přípony řetězce jsou , C, BC a ABC.
- Hledáme lps v podvzorcích. Jasněji se zaměřujeme na podřetězce vzorů, které jsou jak předpony, tak přípony.
- Pro každý dílčí vzor pat[0..i], kde i = 0 až m-1, lps[i] ukládá délku maximální shodné správné předpony, která je také příponou dílčího vzoru pat[0..i ].
lps[i] = nejdelší vlastní předpona pat[0..i], která je zároveň příponou pat[0..i].
Poznámka: lps[i] lze také definovat jako nejdelší předponu, která je také správnou příponou. Musíme jej správně použít na jednom místě, abychom se ujistili, že nebude uvažován celý podřetězec.
Příklady konstrukce lps[]:
Pro vzor AAAA je lps[] [0, 1, 2, 3]
Pro vzor ABCDE je lps[] [0, 0, 0, 0, 0]
Pro vzor AABAACAABAA je lps[] [0, 1, 0, 1, 2, 0, 1, 2, 3, 4, 5]
Pro vzor AAACAAAAAC je lps[] [0, 1, 2, 0, 1, 2, 3, 3, 3, 4]
Pro vzor AAABAAA je lps[] [0, 1, 2, 0, 1, 2, 3]
Algoritmus předběžného zpracování:
V části předběžného zpracování
- Počítáme hodnoty v lps[] . Za tímto účelem sledujeme délku nejdelší hodnoty přípony předpony (používáme jen pro tento účel) pro předchozí index
- Inicializujeme lps[0] a jen jako 0.
- Li pat[len] a postele zápas, zvyšujeme jen o 1 a přiřaďte zvýšenou hodnotu lps[i].
- Pokud se pat[i] a pat[len] neshodují a len není 0, aktualizujeme len na lps[len-1]
- Vidět computeLPSArray() v níže uvedeném kódu pro podrobnosti
Ilustrace předběžného zpracování (nebo konstrukce lps[]):
pat[] = AAAAAAA
=> len = 0, i = 0:
- lps[0] je vždy 0, přesuneme se na i = 1
=> len = 0, i = 1:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- uložte jej do lps[i] a proveďte i++.
- Nastavte len = 1, lps[1] = 1, i = 2
=> len = 1, i = 2:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- uložte jej do lps[i] a proveďte i++.
- Nastavte len = 2, lps[2] = 2, i = 3
=> len = 2, i = 3:
- Protože pat[len] a pat[i] se neshodují a len> 0,
- Nastavte len = lps[len-1] = lps[1] = 1
=> len = 1, i = 3:
- Protože pat[len] a pat[i] se neshodují a len> 0,
- len = lps[len-1] = lps[0] = 0
=> len = 0, i = 3:
- Protože pat[len] a pat[i] se neshodují a len = 0,
- Nastavte lps[3] = 0 a i = 4
=> len = 0, i = 4:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- Uložte to do lps[i] a proveďte i++.
- Nastavte len = 1, lps[4] = 1, i = 5
=> len = 1, i = 5:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- Uložte to do lps[i] a proveďte i++.
- Nastavte len = 2, lps[5] = 2, i = 6
=> len = 2, i = 6:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- Uložte to do lps[i] a proveďte i++.
- délka = 3, lps[6] = 3, i = 7
=> len = 3, i = 7:
- Protože pat[len] a pat[i] se neshodují a len> 0,
- Nastavte len = lps[délka-1] = lps[2] = 2
=> len = 2, i = 7:
- Protože pat[len] a pat[i] se shodují, udělejte len++,
- Uložte to do lps[i] a proveďte i++.
- délka = 3, lps[7] = 3, i = 8
Zde se zastavíme, protože jsme zkonstruovali celý lps[].
Implementace KMP algoritmu:
Na rozdíl od Naivní algoritmus , kde posuneme vzor o jeden a porovnáme všechny znaky při každém posunu, použijeme hodnotu z lps[] k rozhodnutí o dalších znacích, které se mají spárovat. Cílem je neshodovat se s postavou, o které víme, že se stejně bude shodovat.
Jak použít lps[] k rozhodování o dalších pozicích (nebo ke zjištění počtu znaků, které mají být přeskočeny)?
- Začneme porovnání pat[j] s j = 0 se znaky aktuálního okna textu.
- Udržujeme shodné znaky txt[i] a pat[j] a neustále zvyšujeme i a j, zatímco pat[j] a txt[i] ponecháváme vhodný .
- Když vidíme a nesoulad
- Víme, že znaky pat[0..j-1] se shodují s txt[i-j...i-1] (Všimněte si, že j začíná 0 a zvyšuje ji pouze v případě shody).
- Také víme (z výše uvedené definice), že lps[j-1] je počet znaků pat[0…j-1], které jsou jak vlastní předponou, tak příponou.
- Z výše uvedených dvou bodů můžeme usoudit, že tyto znaky lps[j-1] nemusíme porovnávat s txt[i-j…i-1], protože víme, že tyto znaky se stejně budou shodovat. Podívejme se na výše uvedený příklad, abychom to pochopili.
Níže je ilustrace výše uvedeného algoritmu:
Zvažte txt[] = AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA , pat[] = AAAA
Pokud budeme postupovat podle výše uvedeného procesu budování LPS lps[] = {0, 1, 2, 3}
-> i = 0, j = 0: txt[i] a pat[j] odpovídají, do i++, j++
-> i = 1, j = 1: txt[i] a pat[j] odpovídají, do i++, j++
-> i = 2, j = 2: txt[i] a pat[j] odpovídají, do i++, j++
-> i = 3, j = 3: txt[i] a pat[j] odpovídají, do i++, j++
-> i = 4, j = 4: Protože j = M, tiskový vzor nalezen a reset j, j = lps[j-1] = lps[3] = 3
Zde na rozdíl od naivního algoritmu neodpovídáme prvním třem
znaky tohoto okna. Hodnota lps[j-1] (ve výše uvedeném kroku) nám poskytla index dalšího znaku, který se má shodovat.-> i = 4, j = 3: txt[i] a pat[j] odpovídají, do i++, j++
-> i = 5, j = 4: Protože j == M, tiskový vzor nalezen a reset j, j = lps[j-1] = lps[3] = 3
Opět na rozdíl od naivního algoritmu neshodujeme první tři znaky tohoto okna. Hodnota lps[j-1] (ve výše uvedeném kroku) nám poskytla index dalšího znaku, který se má shodovat.-> i = 5, j = 3: txt[i] a pat[j] NESHODUJÍ a j> 0, změňte pouze j. j = lps[j-1] = lps[2] = 2
-> i = 5, j = 2: txt[i] a pat[j] NESHODUJÍ a j> 0, změňte pouze j. j = lps[j-1] = lps[1] = 1
-> i = 5, j = 1: txt[i] a pat[j] NESHODUJÍ a j> 0, změňte pouze j. j = lps[j-1] = lps[0] = 0
-> i = 5, j = 0: txt[i] a pat[j] NESHODUJÍ a j je 0, děláme i++.
-> i = 6, j = 0: txt[i] a pat[j] se shodují, proveďte i++ a j++
-> i = 7, j = 1: txt[i] a pat[j] se shodují, proveďte i++ a j++
Takto pokračujeme, dokud není v textu dostatek znaků pro porovnání se znaky ve vzoru…
Níže je uvedena implementace výše uvedeného přístupu:
C++
// C++ program for implementation of KMP pattern searching> // algorithm> #include> void> computeLPSArray(> char> * pat,> int> M,> int> * lps);> // Prints occurrences of pat[] in txt[]> void> KMPSearch(> char> * pat,> char> * txt)> {> > int> M => strlen> (pat);> > int> N => strlen> (txt);> > // create lps[] that will hold the longest prefix suffix> > // values for pattern> > int> lps[M];> > // Preprocess the pattern (calculate lps[] array)> > computeLPSArray(pat, M, lps);> > int> i = 0;> // index for txt[]> > int> j = 0;> // index for pat[]> > while> ((N - i)>= (M - j)) {> > if> (pat[j] == txt[i]) {> > j++;> > i++;> > }> > if> (j == M) {> > printf> (> 'Found pattern at index %d '> , i - j);> > j = lps[j - 1];> > }> > // mismatch after j matches> > else> if> (i // Do not match lps[0..lps[j-1]] characters, // they will match anyway if (j != 0) j = lps[j - 1]; else i = i + 1; } } } // Fills lps[] for given pattern pat[0..M-1] void computeLPSArray(char* pat, int M, int* lps) { // length of the previous longest prefix suffix int len = 0; lps[0] = 0; // lps[0] is always 0 // the loop calculates lps[i] for i = 1 to M-1 int i = 1; while (i if (pat[i] == pat[len]) { len++; lps[i] = len; i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if (len != 0) { len = lps[len - 1]; // Also, note that we do not increment // i here } else // if (len == 0) { lps[i] = 0; i++; } } } } // Driver code int main() { char txt[] = 'ABABDABACDABABCABAB'; char pat[] = 'ABABCABAB'; KMPSearch(pat, txt); return 0; }> |
Jáva
// JAVA program for implementation of KMP pattern> // searching algorithm> class> KMP_String_Matching {> > void> KMPSearch(String pat, String txt)> > {> > int> M = pat.length();> > int> N = txt.length();> > // create lps[] that will hold the longest> > // prefix suffix values for pattern> > int> lps[] => new> int> [M];> > int> j => 0> ;> // index for pat[]> > // Preprocess the pattern (calculate lps[]> > // array)> > computeLPSArray(pat, M, lps);> > int> i => 0> ;> // index for txt[]> > while> ((N - i)>= (M - j)) {> > if> (pat.charAt(j) == txt.charAt(i)) {> > j++;> > i++;> > }> > if> (j == M) {> > System.out.println(> 'Found pattern '> > +> 'at index '> + (i - j));> > j = lps[j -> 1> ];> > }> > // mismatch after j matches> > else> if> (i && pat.charAt(j) != txt.charAt(i)) { // Do not match lps[0..lps[j-1]] characters, // they will match anyway if (j != 0) j = lps[j - 1]; else i = i + 1; } } } void computeLPSArray(String pat, int M, int lps[]) { // length of the previous longest prefix suffix int len = 0; int i = 1; lps[0] = 0; // lps[0] is always 0 // the loop calculates lps[i] for i = 1 to M-1 while (i if (pat.charAt(i) == pat.charAt(len)) { len++; lps[i] = len; i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if (len != 0) { len = lps[len - 1]; // Also, note that we do not increment // i here } else // if (len == 0) { lps[i] = len; i++; } } } } // Driver code public static void main(String args[]) { String txt = 'ABABDABACDABABCABAB'; String pat = 'ABABCABAB'; new KMP_String_Matching().KMPSearch(pat, txt); } } // This code has been contributed by Amit Khandelwal.> |
Python3
# Python3 program for KMP Algorithm> def> KMPSearch(pat, txt):> > M> => len> (pat)> > N> => len> (txt)> > # create lps[] that will hold the longest prefix suffix> > # values for pattern> > lps> => [> 0> ]> *> M> > j> => 0> # index for pat[]> > # Preprocess the pattern (calculate lps[] array)> > computeLPSArray(pat, M, lps)> > i> => 0> # index for txt[]> > while> (N> -> i)>> => (M> -> j):> > if> pat[j]> => => txt[i]:> > i> +> => 1> > j> +> => 1> > if> j> => => M:> > print> (> 'Found pattern at index '> +> str> (i> -> j))> > j> => lps[j> -> 1> ]> > # mismatch after j matches> > elif> i and pat[j] != txt[i]: # Do not match lps[0..lps[j-1]] characters, # they will match anyway if j != 0: j = lps[j-1] else: i += 1 # Function to compute LPS array def computeLPSArray(pat, M, lps): len = 0 # length of the previous longest prefix suffix lps[0] = 0 # lps[0] is always 0 i = 1 # the loop calculates lps[i] for i = 1 to M-1 while i if pat[i] == pat[len]: len += 1 lps[i] = len i += 1 else: # This is tricky. Consider the example. # AAACAAAA and i = 7. The idea is similar # to search step. if len != 0: len = lps[len-1] # Also, note that we do not increment i here else: lps[i] = 0 i += 1 # Driver code if __name__ == '__main__': txt = 'ABABDABACDABABCABAB' pat = 'ABABCABAB' KMPSearch(pat, txt) # This code is contributed by Bhavya Jain> |
C#
// C# program for implementation of KMP pattern> // searching algorithm> using> System;> class> GFG {> > void> KMPSearch(> string> pat,> string> txt)> > {> > int> M = pat.Length;> > int> N = txt.Length;> > // Create lps[] that will hold the longest> > // prefix suffix values for pattern> > int> [] lps => new> int> [M];> > // Index for pat[]> > int> j = 0;> > // Preprocess the pattern (calculate lps[]> > // array)> > computeLPSArray(pat, M, lps);> > int> i = 0;> > while> ((N - i)>= (M - j)) {> > if> (pat[j] == txt[i]) {> > j++;> > i++;> > }> > if> (j == M) {> > Console.Write(> 'Found pattern '> > +> 'at index '> + (i - j));> > j = lps[j - 1];> > }> > // Mismatch after j matches> > else> if> (i // Do not match lps[0..lps[j-1]] characters, // they will match anyway if (j != 0) j = lps[j - 1]; else i = i + 1; } } } void computeLPSArray(string pat, int M, int[] lps) { // Length of the previous longest prefix suffix int len = 0; int i = 1; lps[0] = 0; // The loop calculates lps[i] for i = 1 to M-1 while (i if (pat[i] == pat[len]) { len++; lps[i] = len; i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if (len != 0) { len = lps[len - 1]; // Also, note that we do not increment // i here } else // len = 0 { lps[i] = len; i++; } } } } // Driver code public static void Main() { string txt = 'ABABDABACDABABCABAB'; string pat = 'ABABCABAB'; new GFG().KMPSearch(pat, txt); } } // This code has been contributed by Amit Khandelwal.> |
Javascript
> > //Javascript program for implementation of KMP pattern> > // searching algorithm> > > function> computeLPSArray(pat, M, lps)> > {> > // length of the previous longest prefix suffix> > var> len = 0;> > var> i = 1;> > lps[0] = 0;> // lps[0] is always 0> > > // the loop calculates lps[i] for i = 1 to M-1> > while> (i if (pat.charAt(i) == pat.charAt(len)) { len++; lps[i] = len; i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if (len != 0) { len = lps[len - 1]; // Also, note that we do not increment // i here } else // if (len == 0) { lps[i] = len; i++; } } } } function KMPSearch(pat,txt) { var M = pat.length; var N = txt.length; // create lps[] that will hold the longest // prefix suffix values for pattern var lps = []; var j = 0; // index for pat[] // Preprocess the pattern (calculate lps[] // array) computeLPSArray(pat, M, lps); var i = 0; // index for txt[] while ((N - i)>= (M - j)) { if (pat.charAt(j) == txt.charAt(i)) { j++; i++; } if (j == M) { document.write('Nalezený vzor ' + 'na indexu ' + (i - j) + '
'); j = lps[j - 1]; } // neshoda po j odpovídá else if (i // Neodpovídají lps[0..lps[j-1]] znakům, // budou se stejně shodovat, pokud (j != 0) j = lps[j - 1 ]; else i = i + 1 } var txt = 'ABABDABACDABABCABAB'; |
>
// PHP program for implementation of KMP pattern searching // algorithm // Prints occurrences of txt[] in pat[] function KMPSearch($pat, $txt) { $M = strlen($pat); $N = strlen($txt); // create lps[] that will hold the longest prefix suffix // values for pattern $lps=array_fill(0,$M,0); // Preprocess the pattern (calculate lps[] array) computeLPSArray($pat, $M, $lps); $i = 0; // index for txt[] $j = 0; // index for pat[] while (($N - $i)>= ($M - $j)) { if ($pat[$j] == $txt[$i]) { $j++; $i++; } if ($j == $M) { printf('Nalezen vzor na indexu '.($i - $j)); $j = $lps[$j - 1]; } // neshoda po j odpovídá else if ($i <$N && $pat[$j] != $txt[$i]) { // Do not match lps[0..lps[j-1]] characters, // they will match anyway if ($j != 0) $j = $lps[$j - 1]; else $i = $i + 1; } } } // Fills lps[] for given pattern pat[0..M-1] function computeLPSArray($pat, $M, &$lps) { // Length of the previous longest prefix suffix $len = 0; $lps[0] = 0; // lps[0] is always 0 // The loop calculates lps[i] for i = 1 to M-1 $i = 1; while ($i <$M) { if ($pat[$i] == $pat[$len]) { $len++; $lps[$i] = $len; $i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if ($len != 0) { $len = $lps[$len - 1]; // Also, note that we do not increment // i here } else // if (len == 0) { $lps[$i] = 0; $i++; } } } } // Driver program to test above function $txt = 'ABABDABACDABABCABAB'; $pat = 'ABABCABAB'; KMPSearch($pat, $txt); // This code is contributed by chandan_jnu ?>>
Výstup
Found pattern at index 10Časová náročnost: O(N+M) kde N je délka textu a M je délka nalezeného vzoru.
Pomocný prostor: O(M)