Skupina posunutý řetězec


Vzhledem k poli řetězců (všechna malá písmena) je úkolem je seskupit tak, aby všechny řetězce ve skupině byly navzájem posunutými verzemi.
Dvě struny s1 a s2 se nazývají posunuté, pokud jsou splněny následující podmínky:
- s1.délka se rovná s2.délka
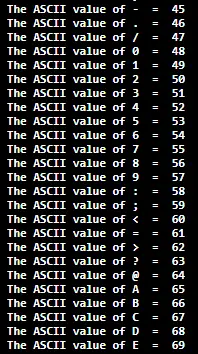
- s1[i] se rovná s2[i] + m za všechny 1 <= i <= s1.length for a konstantní celé číslo m. Posouvání považujte za cyklické, to znamená, že pokud s2[i] + m > 'z', pak začněte od 'a' nebo pokud s2[i] + m < 'a' then start from 'z'.
Příklady:
Vstup: arr[] = ['acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs']
výstup: [ ['acd' 'dfg' 'wyz' 'yab' 'mop'] ['bdfh' 'moqs'] ['a' 'x'] ]
Vysvětlení: Všechny posunuté řetězce jsou seskupeny.
Vstup: arr = ['geek' 'for' 'geeks']
výstup: [['for'] ['geek'] ['geeks']]
Přístup: Použití Hash Map
C++Cílem je vytvořit jedinečný hash pro každou skupinu podle normalizace struny. Zde normalizace znamená, že první znak každého řetězce bude roven 'a' výpočtem požadovaného směny a aplikovat jej jednotně na všechny znaky v cyklická móda .
Příklad: s = 'dca' posuny = 'd' - 'a' = 3
normalizované znaky: 'd' - 3 = 'a' 'c' - 3 = 'z' a 'a' - 3 = 'x'
normalizovaný řetězec = 'azx'The normalizovaný řetězec (hash) představuje vzor řazení tak, že řetězce se stejným vzorem mají stejný hash. Ke sledování těchto hashů a jejich mapování do odpovídajících skupin používáme hash mapu. Pro každý řetězec vypočítáme hash a použijeme ho k vytvoření nové skupiny nebo přidání řetězce do existující skupiny v jediném průchodu.
// C++ program to print groups of shifted strings // together using Hash Map #include #include #include using namespace std ; // Function to generate hash by shifting and equating // the first character string getHash ( string s ) { // Calculate the shift needed to normalize the string int shifts = s [ 0 ] - 'a' ; for ( char & ch : s ) { // Adjust each character by the shift ch = ch - shifts ; // Wrap around if the character goes below 'a' if ( ch < 'a' ) ch += 26 ; } return s ; } // Function to group shifted string together vector < vector < string >> groupShiftedString ( vector < string > & arr ) { vector < vector < string >> res ; // Maps hash to index in result unordered_map < string int > mp ; for ( string s : arr ) { // Generate hash representing the shift pattern string hash = getHash ( s ); // If new hash create a new group if ( mp . find ( hash ) == mp . end ()) { mp [ hash ] = res . size (); res . push_back ({}); } // Add string to its group res [ mp [ hash ]]. push_back ( s ); } return res ; } int main () { vector < string > arr = { 'acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs' }; vector < vector < string >> groups = groupShiftedString ( arr ); for ( vector < string > & group : groups ) { for ( string & s : group ) { cout < < s < < ' ' ; } cout < < endl ; } return 0 ; }
Java // Java program to print groups of shifted strings // together using Hash Map import java.util.* ; class GfG { // Function to generate hash by shifting and equating the // first character static String getHash ( String s ) { // Calculate the shift needed to normalize the string int shifts = s . charAt ( 0 ) - 'a' ; char [] chars = s . toCharArray (); for ( int i = 0 ; i < chars . length ; i ++ ) { // Adjust each character by the shift chars [ i ] = ( char ) ( chars [ i ] - shifts ); // Wrap around if the character goes below 'a' if ( chars [ i ] < 'a' ) chars [ i ] += 26 ; } return new String ( chars ); } // Function to group shifted strings together static ArrayList < ArrayList < String >> groupShiftedString ( String [] arr ) { ArrayList < ArrayList < String >> res = new ArrayList <> (); // Maps hash to index in result HashMap < String Integer > mp = new HashMap <> (); for ( String s : arr ) { // Generate hash representing the shift pattern String hash = getHash ( s ); // If new hash create a new group if ( ! mp . containsKey ( hash )) { mp . put ( hash res . size ()); res . add ( new ArrayList <> ()); } // Add string to its group res . get ( mp . get ( hash )). add ( s ); } return res ; } public static void main ( String [] args ) { String [] arr = { 'acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs' }; ArrayList < ArrayList < String >> groups = groupShiftedString ( arr ); for ( ArrayList < String > group : groups ) { for ( String s : group ) { System . out . print ( s + ' ' ); } System . out . println (); } } }
Python # Python program to print groups of shifted strings # together using Hash Map # Function to generate hash by shifting and equating the first character def getHash ( s ): # Calculate the shift needed to normalize the string shifts = ord ( s [ 0 ]) - ord ( 'a' ) hashVal = [] for ch in s : # Adjust each character by the shift newCh = chr ( ord ( ch ) - shifts ) # Wrap around if the character goes below 'a' if newCh < 'a' : newCh = chr ( ord ( newCh ) + 26 ) hashVal . append ( newCh ) return '' . join ( hashVal ) # Function to group shifted strings together def groupShiftedString ( arr ): res = [] # Maps hash to index in result mp = {} for s in arr : # Generate hash representing the shift pattern hashVal = getHash ( s ) # If new hash create a new group if hashVal not in mp : mp [ hashVal ] = len ( res ) res . append ([]) # Add string to its group res [ mp [ hashVal ]] . append ( s ) return res if __name__ == '__main__' : arr = [ 'acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs' ] groups = groupShiftedString ( arr ) for group in groups : print ( ' ' . join ( group ))
C# // C# program to print groups of shifted strings // together using Hash Map using System ; using System.Collections.Generic ; class GfG { // Function to generate hash by shifting and equating the first character static string getHash ( string s ) { // Calculate the shift needed to normalize the string int shifts = s [ 0 ] - 'a' ; char [] chars = s . ToCharArray (); for ( int i = 0 ; i < chars . Length ; i ++ ) { // Adjust each character by the shift chars [ i ] = ( char )( chars [ i ] - shifts ); // Wrap around if the character goes below 'a' if ( chars [ i ] < 'a' ) chars [ i ] += ( char ) 26 ; } return new string ( chars ); } // Function to group shifted strings together static List < List < string >> groupShiftedString ( string [] arr ) { List < List < string >> res = new List < List < string >> (); // Maps hash to index in result Dictionary < string int > mp = new Dictionary < string int > (); foreach ( string s in arr ) { // Generate hash representing the shift pattern string hash = getHash ( s ); // If new hash create a new group if ( ! mp . ContainsKey ( hash )) { mp [ hash ] = res . Count ; res . Add ( new List < string > ()); } // Add string to its group res [ mp [ hash ]]. Add ( s ); } return res ; } static void Main ( string [] args ) { string [] arr = { 'acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs' }; var groups = groupShiftedString ( arr ); foreach ( var group in groups ) { Console . WriteLine ( string . Join ( ' ' group )); } } }
JavaScript // JavaScript program to print groups of shifted strings // together using Hash Map // Function to generate hash by shifting and equating the first character function getHash ( s ) { // Calculate the shift needed to normalize the string const shifts = s . charCodeAt ( 0 ) - 'a' . charCodeAt ( 0 ); let chars = []; for ( let ch of s ) { // Adjust each character by the shift let newChar = String . fromCharCode ( ch . charCodeAt ( 0 ) - shifts ); // Wrap around if the character goes below 'a' if ( newChar < 'a' ) newChar = String . fromCharCode ( newChar . charCodeAt ( 0 ) + 26 ); chars . push ( newChar ); } return chars . join ( '' ); } // Function to group shifted strings together function groupShiftedString ( arr ) { const res = []; // Maps hash to index in result const mp = new Map (); for ( let s of arr ) { // Generate hash representing the shift pattern const hash = getHash ( s ); // If new hash create a new group if ( ! mp . has ( hash )) { mp . set ( hash res . length ); res . push ([]); } // Add string to its group res [ mp . get ( hash )]. push ( s ); } return res ; } // Driver Code const arr = [ 'acd' 'dfg' 'wyz' 'yab' 'mop' 'bdfh' 'a' 'x' 'moqs' ]; const groups = groupShiftedString ( arr ); groups . forEach ( group => console . log ( group . join ( ' ' )));
Výstup
acd dfg wyz yab mop bdfh moqs a x
Časová náročnost: O(n*k) kde n je délka pole řetězců a k je maximální délka řetězce v poli řetězců.
Pomocný prostor: O(n*k) v nejhorším případě bychom mohli vygenerovat n různých hashových řetězců pro každý vstupní řetězec. Takže máme n různých položek v hash mapě, každá o délce k nebo menší.