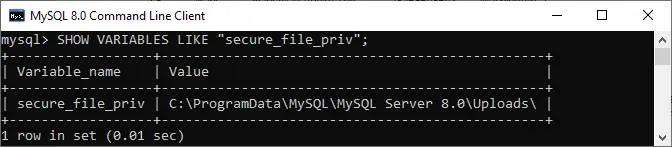
Анализ на XML в Python

Тази статия се фокусира върху това как човек може да анализира даден XML файл и да извлече някои полезни данни от него по структуриран начин. XML: XML означава eXtensible Markup Language. Той е проектиран да съхранява и пренася данни. Той е проектиран да бъде както човешко, така и машинно четимо. Ето защо целите на дизайна на XML наблягат на простотата, общоприетостта и използваемостта в Интернет. XML файлът, който ще бъде анализиран в този урок, всъщност е RSS емисия. RSS: RSS (Rich Site Summary, често наричан Really Simple Syndication) използва група от стандартни формати за уеб емисии, за да публикува често актуализирана информация, като записи в блогове, заглавия на новини, аудио, видео. RSS е XML форматиран обикновен текст.
- Самият RSS формат е относително лесен за четене както от автоматизирани процеси, така и от хора.
- RSS, обработен в този урок, е RSS емисия на водещи новини от популярен новинарски уебсайт. Можете да го проверите тук . Нашата цел е да обработим тази RSS емисия (или XML файл) и да я запазим в друг формат за бъдеща употреба.
#Python code to illustrate parsing of XML files # importing the required modules import csv import requests import xml.etree.ElementTree as ET def loadRSS (): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests . get ( url ) # saving the xml file with open ( 'topnewsfeed.xml' 'wb' ) as f : f . write ( resp . content ) def parseXML ( xmlfile ): # create element tree object tree = ET . parse ( xmlfile ) # get root element root = tree . getroot () # create empty list for news items newsitems = [] # iterate news items for item in root . findall ( './channel/item' ): # empty news dictionary news = {} # iterate child elements of item for child in item : # special checking for namespace object content:media if child . tag == '{https://video.search.yahoo.com/mrss' : news [ 'media' ] = child . attrib [ 'url' ] else : news [ child . tag ] = child . text . encode ( 'utf8' ) # append news dictionary to news items list newsitems . append ( news ) # return news items list return newsitems def savetoCSV ( newsitems filename ): # specifying the fields for csv file fields = [ 'guid' 'title' 'pubDate' 'description' 'link' 'media' ] # writing to csv file with open ( filename 'w' ) as csvfile : # creating a csv dict writer object writer = csv . DictWriter ( csvfile fieldnames = fields ) # writing headers (field names) writer . writeheader () # writing data rows writer . writerows ( newsitems ) def main (): # load rss from web to update existing xml file loadRSS () # parse xml file newsitems = parseXML ( 'topnewsfeed.xml' ) # store news items in a csv file savetoCSV ( newsitems 'topnews.csv' ) if __name__ == '__main__' : # calling main function main ()
Above code will: - Заредете RSS емисия от посочения URL адрес и я запазете като XML файл.
- Анализирайте XML файла, за да запазите новините като списък с речници, където всеки речник е отделна новина.
- Запазете новините в CSV файл.
- Можете да разгледате още rss емисии на новинарския уебсайт, използван в горния пример. Можете да опитате да създадете разширена версия на горния пример, като анализирате и други rss емисии.
- Вие сте фен на крикета? Тогава това RSS емисията трябва да ви интересува! Можете да анализирате този XML файл, за да изтриете информация за мачовете по крикет на живо и да го използвате, за да направите десктоп нотификатор!
def loadRSS(): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests.get(url) # saving the xml file with open('topnewsfeed.xml' 'wb') as f: f.write(resp.content) Here we first created a HTTP response object by sending an HTTP request to the URL of the RSS feed. The content of response now contains the XML file data which we save as topnewsfeed.xml в нашия локален указател. За повече информация как работи модулът за заявки, следвайте тази статия: GET и POST заявки с помощта на Python  Тук използваме xml.etree.ElementTree (наричайте го накратко ET) модул. Element Tree има два класа за тази цел - ElementTree представя целия XML документ като дърво и елемент представлява единичен възел в това дърво. Взаимодействията с целия документ (четене и запис към/от файлове) обикновено се извършват на ElementTree ниво. Взаимодействията с един XML елемент и неговите поделементи се извършват на елемент ниво. Добре, нека да преминем през parseXML() function now:
Тук използваме xml.etree.ElementTree (наричайте го накратко ET) модул. Element Tree има два класа за тази цел - ElementTree представя целия XML документ като дърво и елемент представлява единичен възел в това дърво. Взаимодействията с целия документ (четене и запис към/от файлове) обикновено се извършват на ElementTree ниво. Взаимодействията с един XML елемент и неговите поделементи се извършват на елемент ниво. Добре, нека да преминем през parseXML() function now: tree = ET.parse(xmlfile)Here we create an ElementTree обект чрез анализиране на преминалия xmlфайл.
root = tree.getroot()getrooted() функция връща корена на дърво като елемент object.
for item in root.findall('./channel/item'): Now once you have taken a look at the structure of your XML file you will notice that we are interested only in елемент елемент. ./канал/елемент всъщност е XPath синтаксис (XPath е език за адресиране на части от XML документ). Тук искаме да намерим всички елемент внуци на канал деца на корен (обозначен с '.') елемент. Можете да прочетете повече за поддържания синтаксис на XPath тук . for item in root.findall('./channel/item'): # empty news dictionary news = {} # iterate child elements of item for child in item: # special checking for namespace object content:media if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] else: news[child.tag] = child.text.encode('utf8') # append news dictionary to news items list newsitems.append(news) Now we know that we are iterating through елемент елементи, където всеки елемент елемент съдържа една новина. Така че създаваме празен новини dictionary in which we will store all data available about news item. To iterate though each child element of an element we simply iterate through it like this: for child in item:Now notice a sample item element here:
 We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this:
We will have to handle namespace tags separately as they get expanded to their original value when parsed. So we do something like this: if child.tag == '{https://video.search.yahoo.com/mrss': news['media'] = child.attrib['url'] дете.аттриб е речник на всички атрибути, свързани с даден елемент. Тук се интересуваме от URL адрес атрибут на медии: съдържание namespace tag. Now for all other children we simply do: news[child.tag] = child.text.encode('utf8') child.tag съдържа името на дъщерния елемент. дете.текст stores all the text inside that child element. So finally a sample item element is converted to a dictionary and looks like this: {'description': 'Ignis has a tough competition already from Hyun.... 'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... 'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... 'pubDate': 'Thu 12 Jan 2017 12:33:04 GMT ' 'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... } Then we simply append this dict element to the list новинарски сайтове . Накрая този списък се връща.  Както можете да видите, йерархичните XML файлови данни са преобразувани в обикновен CSV файл, така че всички новини да се съхраняват под формата на таблица. Това улеснява и разширяването на базата данни. Също така човек може да използва JSON-подобни данни директно в своите приложения! Това е най-добрата алтернатива за извличане на данни от уебсайтове, които не предоставят публичен API, но предоставят някои RSS канали. Всички кодове и файлове, използвани в горната статия, могат да бъдат намерени тук . Какво следва?
Както можете да видите, йерархичните XML файлови данни са преобразувани в обикновен CSV файл, така че всички новини да се съхраняват под формата на таблица. Това улеснява и разширяването на базата данни. Също така човек може да използва JSON-подобни данни директно в своите приложения! Това е най-добрата алтернатива за извличане на данни от уебсайтове, които не предоставят публичен API, но предоставят някои RSS канали. Всички кодове и файлове, използвани в горната статия, могат да бъдат намерени тук . Какво следва? Може Да Ви Хареса

Топ Статии




Категория
Интересни Статии