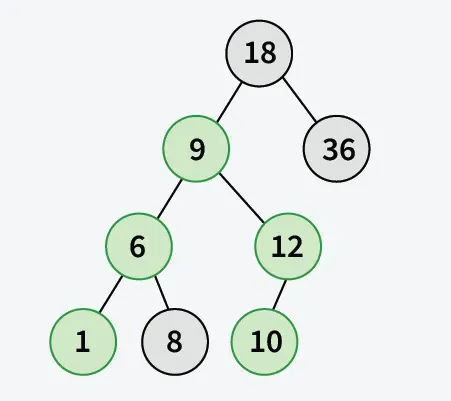
Токенизирайте текст с помощта на NLTK в python
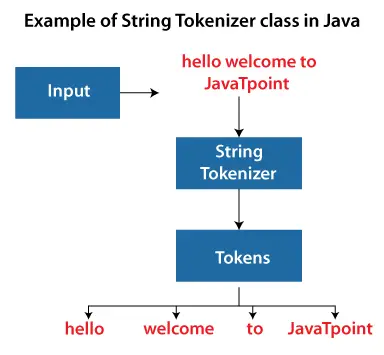
Текстовото токенизиране е фундаментална техника за обработка на естествен език (NLP) и една такава техника е Токенизация. Това е процес на разделяне на текст на по-малки компоненти или токени. Те могат да бъдат:
- Думи: I love NLP → ['I' 'love' 'NLP']
- Изречения: Обичам НЛП. Python е страхотен. → ['Обичам НЛП.' „Python е страхотен.“]
С популярната библиотека на Python NLTK (Natural Language Toolkit) разделянето на текст на смислени единици става както просто, така и изключително ефективно.
Основно изпълнение
Нека да видим реализацията на токенизация с помощта на NLTK в Python
Стъпка 1: Инсталиране и настройка
Инсталирайте точка модели на токенизатори, необходими за токенизиране на изречения и думи.
Python ! pip install nltk import nltk nltk . download ( 'punkt' )
Стъпка 2: Токенизиране на изречения
sent_tokenize() разделя низ на списък от изречения, обработващи пунктуация и съкращения.
Python from nltk.tokenize import sent_tokenize text = 'NLTK is a great NLP toolkit. It makes processing text easy!' sentences = sent_tokenize ( text ) print ( sentences )
Изход:
[„NLTK е страхотен инструментариум за НЛП.“ „Улеснява обработката на текст!“]
Стъпка 3: Токенизиране на думи
- word_tokenize() разделя изречение на думи и препинателни знаци като отделни токени.
- Обработва контракции, препинателни числа и др.
from nltk.tokenize import word_tokenize sentence = 'Tokenization is easy with NLTK's word_tokenize.' words = word_tokenize ( sentence ) print ( words )
Изход:
['Токенизирането' 'е' 'лесно' 'с' 'NLTK' ''s' 'word_tokenize' '.']
Да видим още няколко примера
1. WordPunctTokenizer
то Разделя текста на азбучни и неазбучни знаци
- Разделя всички поредици от знаци на думи и препинателни знаци в токени.
- Особено разделя контракциите (Don't става Don't).
- Разделя имейлите на електронни писма.
from nltk.tokenize import WordPunctTokenizer tokenizer = WordPunctTokenizer () tokens = tokenizer . tokenize ( 'Don't split contractions. E-mails: [email protected]!' ) print ( tokens )
Изход:
['Не' ''' 't' 'разделяне' 'контракции' '.' 'E' '-' 'mails' ':' 'hello' '@' 'example' '.' 'com' '!']
2. TreebankWordTokenizer
Подходящ е за лингвистичен анализ, обработва пунктуация и съкращения.
- Имитира токенизиране в стил Penn Treebank, което обикновено се използва за NLP лингвистичен анализ.
- Борави с определени английски граматически структури по-интелигентно.
from nltk.tokenize import TreebankWordTokenizer tokenizer = TreebankWordTokenizer () tokens = tokenizer . tokenize ( 'Have a look at NLTK's tokenizers.' ) print ( tokens )
Изход:
['Разгледайте' 'NLTK' ''s' 'токенизатори' '.']
3. Regex Tokenizer
Той персонализира разделянето на базата на шаблони.
- Токенизира въз основа на модел на регулярен израз.
- w+ съвпада с думи и числа, пропускащи напълно пунктуацията.
from nltk.tokenize import RegexpTokenizer tokenizer = RegexpTokenizer ( r 'w+' ) tokens = tokenizer . tokenize ( 'Custom rule: keep only words & numbers drop punctuation!' ) print ( tokens )
Изход:
['Custom' 'rule' 'keep' 'only' 'words' 'numbers' 'drop' 'punctuation']
NLTK предоставя полезен и удобен за потребителя набор от инструменти за токенизиране на текст в Python, поддържащ набор от нужди за токенизиране от основно разделяне на думи и изречения до разширени потребителски модели.
Създаване на тест